编者按:本文来自微信公众号 星海情报局(ID:junwu2333),作者:星海老局悉地网经授权转载。
今年年初的时候,我给我爸妈演示了某款面向C端市场的AI产品。他们之前几乎没有接触过任何形式的AI大模型,所以当我给他们谈起现在的AI技术有多发达的时候,他们还以为这不过是siri这种语音助手的变种。
但在我通过语音通话的形式给AI提出问题并得到非常自然、流畅的回答后,我爸妈整个就震惊到了——他们用一种不可思议的目光看着我,问出了一个经典的问题:
“刚才和你对话的那个,难道不是真人吗?”
AI数字人示意图
在我让他们尝试玩了几次之后,他们才终于确信:原来刚刚真的是在和AI打交道。后来的一两天 ,我爸也下载了这款AI产品,玩得不亦乐乎。甚至一个星期后,我爸还在给我分 享他让AI写的诗、画的画。
然后,就没有然后了。
因为这款AI产品带来的新鲜感已经淡了。
最近几天,科技圈子里最热门的话题应该是被称作“科技春晚”的苹果iPhone发布会。
但显然,苹果的“科技春晚”和“春晚”一样,吸引力已经大不如前了——再也不复当年iPhone5S发布时 候的那种盛况——反倒是华为的三折叠手机引起了不少讨论。

可能这就是一个面 向消费者的市场的残酷性所在:消费者是很容易喜新厌旧的,如果你不能持续带来新的东西,那么很快,你的市场就会被竞争对手所蚕食——支撑iPhone当年地位的是前所未有的创新体验,但现在,随着整个智能手机供应链的崛起,各家的产品都已经来到了一个相当高的层次——iPhone可能再也不会给我们带来当年的那种新鲜感了。
看看现在的AI,感觉似乎也是如此故事。而且由于大模型的迭代速度远高于芯片,相应地,“下头速度”自然也会更快一些。
就在上周末,一张来路不明、显示Chat-GPT访问量断崖式下跌的图就引发了华尔街的一阵动荡,紧跟着就是英伟达、谷歌、亚马逊、Meta这些AI企业的股价下跌。
网图,似乎是个大乌龙
虽然最终被证明是乌龙一场,但这种鸡飞狗跳的画面也挺搞笑的:
如果你真的坚信AI是未来,
又怎么会被一张来路不明的网图所蛊惑?
你对AI的信仰,
原来如此脆弱吗?
今天,我们就来聊聊:现在这个版本的AI故事,究竟还能讲多久。
我曾经遇到过一些闪婚的情侣:初见的时候什么都好,朋友圈里全是什么“斯人若彩虹,遇上方知有”的狗粮;但过了几个月正常日子之后,私下喝酒时候,他们就开始给我吐槽各种琐事和争吵。
人还是那俩人,都是好同志,
但场景变了,现在真的要事儿上见了。
因为现实生活里的问题,实在是太多样太具体了:换下的衣服及时清洗了吗?厨房的碗筷洗干净了吗?菜买多了还是买少了?昨晚为什么没有把垃圾扔出去?宠物最近饭量下降了是不是要去医院看看?中秋节假期快要到了,是不是要回老家看看爸妈……
这些零散、琐碎、不涉及大是大非的问题,却往往能导致一场火爆的争吵,而案值往往不超过20元。
当事人往往会觉得自己瞎了眼了,但我们都知道,这并不是眼瞎不眼瞎的问题:
新鲜感过了,你开始用另一种更务实的KPI体系去衡量对方了,不再是热恋期那样单纯看脸或者看性格了。
我们对当前这一波由Chat-GPT所引领的生成式AI的态度,其实也是如此。
一年多前,当Chat-GPT刚刚面世的时候,整个世界都为之惊叹——因为它确实体现出了强大的智慧,它真的可以理解我们在说什么,还能像模像样回答问题,还能和我们聊的有来有回,尤其是处理翻译任务的时候,大模型几乎吊打一切翻译软件。
但很快,整个市场就充满了竞争者。
大模型终究不是光刻机,Chat-GPT证明了生成式AI的未来后,潜伏的竞争者们立刻就一拥而上——不论是美国本土的Claude.ai还是中国的文心一言和通义千问,从技术到体验,都迅速跟上了Chat-GPT的节奏。
然后,我们和AI的“热恋期”也就到此为止了,因为我们也要用一套更务实的眼光来看AI了。用更专业的说法就是,大家对AI的态度正在“回归理性”。
然后,大家才发现:原来AI也不过如此。
当下的AI,似乎只能处理我们的“低端需求”:
我曾经让AI帮我出一个文章大纲,它反应倒是挺迅速,从原因到影响给我列了几十条出来,但根本经不起细看,因为它完全没有主次的概念——我那篇文章的重点就是去讲述事情背后的原因,结果AI把原因分析部分只当成了一个平平无奇的章节。
七月份我去北京出差,期间和朋友约在某个烧烤店吃饭,拿到菜单我就乐了。因为菜单上的背景图画一眼看上就去就知道是AI的手笔——又把人物的手画成麻花了。

我也曾经试着让AI帮我仿照王维的风格写一首“气质清冷”的诗,结果AI马上就给我端上来一个“老干部体”,吓得我赶紧关了。
至于AI谱曲更是离谱,反正我自己作词让AI帮我编了曲之后,听了三秒就把耳机扯下来了,实在太TM尴尬了,我这种脸皮薄的人如果再听一分钟估计就直接进ICU了。
……
用我朋友对AI的形容就是:每次用AI辅助工作,给他的感觉都像是在给一个刚出校园的实习生布置任务——年轻人是真的勤奋又听话,就是脑子不太好,活儿干的太糙了,只能做最些最基本的事情。
大模型厂商们总是在忧虑DAU和使用时间的问题,不得不说,他们的担心是有理由的。以当下诸多AI产品在现实中的运用体验来说,确实很难让人把AI当成可靠的工具或者相熟的搭档。
AI落地,应该成为工具,而不是玩具,AI应该作为我们打工人的老师傅,而不是还需要我亲自去“传帮带”的实习生。
为啥这一届的AI产品只能满足一些低层次需要呢?为啥感觉AI似乎也不过如此呢?
这件事,还是要从底层的技术原理上来讲。
以Chat-GPT为例,打造一个像Chat-GPT一样的大语言模型,大概需要如下几个环节:
首先你需要海量的数据,可以是各种小说,可以是各种新闻,也可以是各种视频、音频,但总之,你需要准备一个足够大的“语料库”让它去学习,而且为了提高它的学习效率,你还要把这些资料都给做成标准化的数据,让模型能更好接收。
之后,像Chat-GPT这样的大模型基本都是基于Transformer架构,这种架构我们就不多说了,说起来太复杂,我们只需要知道,这种架构的用途在于它可以按照我们人类说话的语法去输出内容,某种意义上相当于是AI的语言中枢和喉舌。
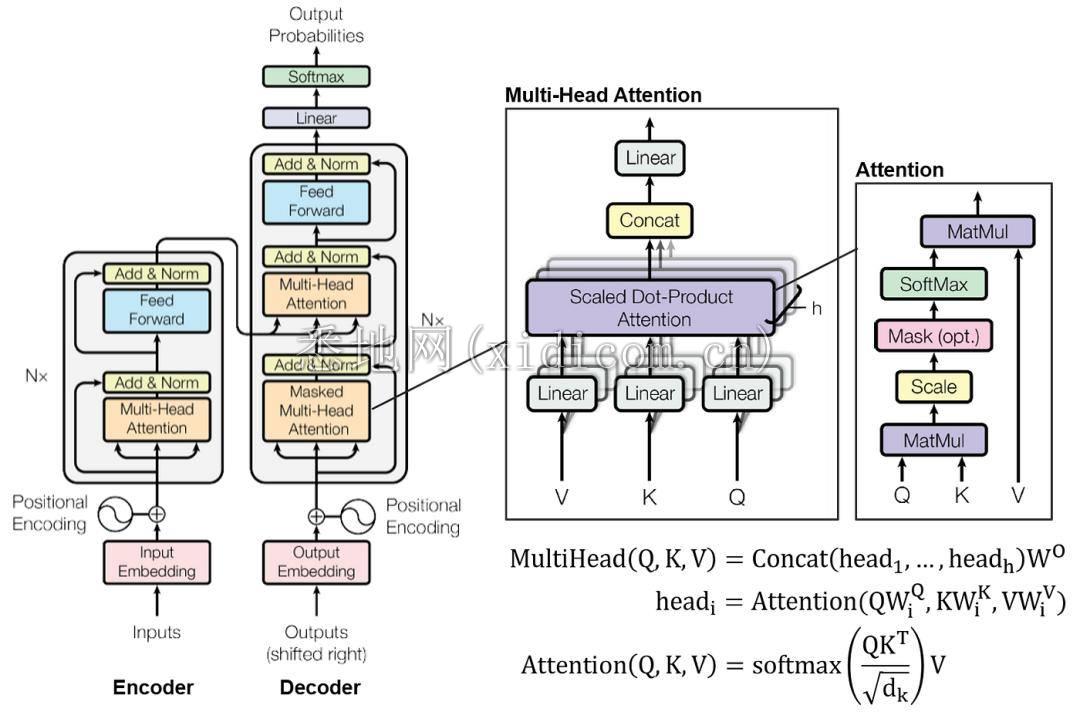
接下来,就是通过各种技术去训练AI,再经过参数调整和一些优化,最终让它能理解我们输入的信息并做出合理的回复。
但是要注意,“合理的回复”并不代表“有用”,更不代表“拟人”——我兄弟给我发一些离谱东西的时候,我通常只会会他一串“哈哈哈哈哈哈”或者单走一个“6”,心情不好了就会回一个“有病吧”。但AI往往会故作礼貌、煞有介事地来一句“这真是一个非常有趣的图片”。
前者虽然不合理,但却很真实。
后者虽然很合理,但却非常不真实。
造成这种尴尬的根本在于其开发的方式:
GPT们采用的是Transformer架构,相比起以前的RNN架构,Transformer能够更好地理解单词和单词之间的顺序关系,可以让大语言模型的训练速度显著提高,而且能够判断出一句话里到底哪个词更重要,从而实现像真人一样“有的放矢”。
乍一看好像没啥毛病,但经不起细琢磨。
因为翻来覆去,GPT们做的事情都是在语言上下功夫,在不停地“猜字谜”,而不是在认识世界。
表现在实际运用中就是:你让GPT去做翻译工作,它可以做到99分的水平;但如果让它去解答你的一些疑惑,可能表现就只有六七十分了。
简单粗暴点来说就是:我说天冷了,AI自然会告诉我要穿秋裤。但AI这么说的原因,并不是它知道穿秋裤会让人感觉暖和,而是在它的训练资料里,“天冷”和“秋裤”这俩词总是一起出现——它其实并不知道天冷了该怎么办,但它知道只要你说天冷了,它回一句“穿秋裤”大概率就能过关。
和某些兄弟们常说的“多喝热水”差不多是一个意思。
说到底,这就是AI大模型开发技术上的一个通病:AI的确能理解我说的每一个字,也的确能做出合理的回答——但它做出回答的前提,并不是基于对事物发展规律的认识,而是通过海量数据的学习、通过MLM这样的“猜字谜”训练,给出了一个“看上去还挺靠谱”的回答。
AI视频产品在这个问题上表现得尤其露骨,AI生成的视频虽然有时候在画面细节上可以做到极度仿真,但一旦涉及物理效果就会立刻把猴子屁股露出来——它并不能理解真实世界里的物理碰撞会造成什么结果,它只是在猜你想看什么罢了。
Chat-GPT现在已经进化到了5.0版本(虽然还没有正式上线),功能上当然是一代更比一代强,但这种增强的基础,是它猜字谜的速度越来越快,猜字谜的强度越来越大,而不是真的增长了智慧。
这届AI的故事,还能讲多久?
业内对于这个问题的应对措施,则是祭出了另一种完全不同的思路——强化学习(RL)。
如果说“深度学习”的能力是在于理解语言,在自然语言处理、语音处理上可以表现优异,那么“强化学习”则更像是在学着理解真实世界——外界不会给系统什么指示,系统要自己试着去探索、去尝试,然后在这个探索的过程里获得知识,进而让自己越来越强大。
在这个过程里,系统追求的是让“奖励信号”的最大化。这就像是一场电脑游戏,系统不断地和外界环境互动,每一个动作都会得到“奖励信号”,做的越好,“奖励信号”就越大,为了获得更大的“奖励信号”,系统就要自己学着做出更好的决策。
用更形象一点的话来描述就是:
AI相当于学生,人类则是老师——基于“深度学习”的AI们,它们的用着“人类教师”提供的“数据集”,在学习过程中,也要时时刻刻受着“人类教师”的监督——符合“人类教师”口味的,就会被鼓励,不符合“人类教师”口味的就会被抛弃。
而基于“强化学习”的AI们,则更像是自学成才,“人类教师”只是领进门,修行就要靠它们自己努力了。在很多时候,它们是没有什么“学习资料”或者“监督指导”的,“人类教师”给他们的命令就是不停学习,至于能学成什么样子,其实“人类教师”心里也没底。

所以,我们可以看到:
基于“深度学习”的AI们,在语言理解、语音理解、图像理解上表现极其优秀,因为这些东西的定义权掌握在人类手中,人类随口的一句话,落在AI耳中就如神谕一般不可否定——AI们要做的就是无限贴合人类的口味,让自己表现得和人一样。
而基于“强化学习”的AI们则往往在和人类比高低,不论是自动驾驶系统教育老司机,还是AlphaGo打哭柯洁然后又被AlphaZero打爆,其实都反映出了一个结果:“强化学习”下的AI们,往往能够做的比人类更好——因为人类要吃饭睡觉,但AI不用,在高性能芯片的加持下,AI训练一年所见识过的棋局、游戏,往往比一个职业棋手、职业电竞玩家十辈子见过的都多。
毕竟,根据OpenAI自己的评估体系,像是Chat-GPT这样的AI应用,其实只是最初级的L1水平,不过就是一个聊天机器人、一个有对话能力的AI。而基于强化学习的AI,则能够达到L2级别,也就是能做到和人类一样解决问题的能力。
而现在,我们已经站在了一个关键的时间点上:
因为大语言模型,也开始走“强化学习”的路子了,以后AI说话之前,也要动动脑子了——OpenAI一直在研究的“Strawberry”(草莓)项目,就是一个基于强化学习的大语言模型。
基于强化学习、有自己想法的大模型很可能最近一两年就会上线,
在这样的大背景下,我实在不知道这届AI的故事,还能讲多久。
本文为专栏作者授权悉地网发表,版权归原作者所有。文章系作者个人观点,不代表悉地网立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。


咨询微信客服

0516-6662 4183
立即获取方案或咨询
top